
Digital infrastructure
KIŠIB’s digital infrastructure is designed to ensure the systematic management, long-term preservation, and interoperability of data on West Asian seals and sealings.
Database
All data, including information about the physical artefacts themselves, their provenance or their visual and textual contents, is stored in a MariaDB database. This database provides the backbone of the project.
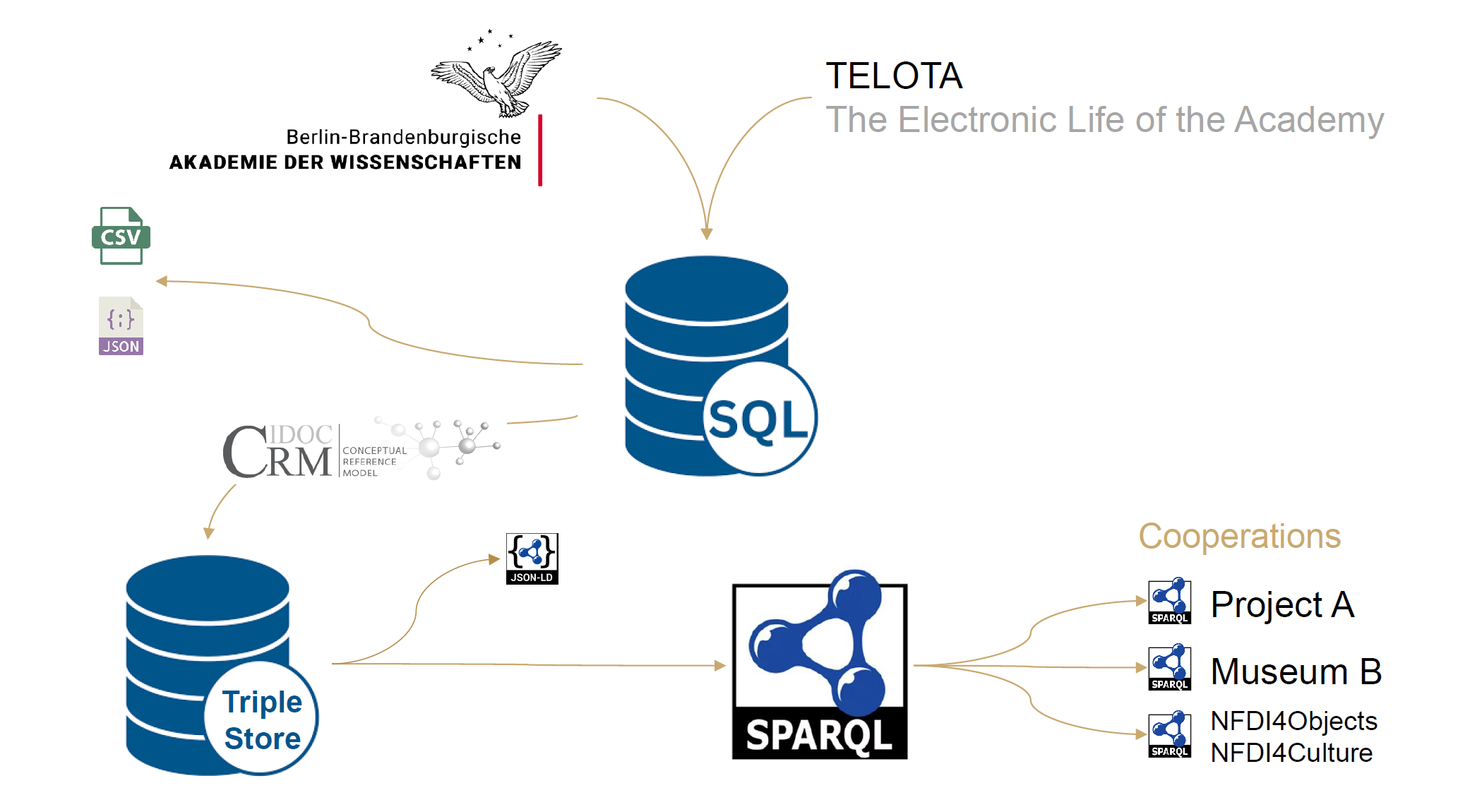
At regular intervals, the data are exported to a Triple Store, enabling RDF-format transfer and integration into semantic web and knowledge graph environments. This approach supports complex queries, enables advanced analysis of relationships among artefacts, images, texts, and social entities, and ensures compatibility with other digital cultural heritage projects. The infrastructure is continuously monitored and updated in consultation with the TELOTA steering group and coordinated with initiatives such as NFDI4culture and NFDI4objects to ensure alignment with best practices in digital cultural heritage management.
Linked Open Data
To ensure long-term sustainability and interoperability, KIŠIB will provide stable URIs and link to existing identifiers in repositories, collections, and archives. The terms used to describe seals and sealed artefacts adhere to controlled vocabularies. These are either provided externally or developed by the KIŠIB team in collaboration with other initiatives and institutions. Where possible, terms are mapped to external authority files such as the Getty Art and Architecture Thesaurus. Where specialised terms are needed, controlled vocabularies will be published in SKOS format and used consistently to annotate pictorial and textual elements. KIŠIB adheres to FAIR and CARE data principles, contributing to an equitable and collaborative model of digital heritage scholarship.
KIŠIB engages with other initiatives dedicated to digital knowledge exchange on ancient West Asia, especially those specialising in cuneiform studies, to ensure that its data remains interoperable and accessible to specialists from various disciplines and to the broader research community. Data can be exported in CSV, JSON, XML, and RDF and accessed through APIs and SPARQL endpoints, facilitating external analyses and integration with other projects. To further increase interoperability, KIŠIB’s data model aligns with the CIDOC Conceptual Reference Model (CRM) and thus uses a well-established semantic ontology for data integration in Cultural Heritage.
Visual records
Good visual records are key to understanding ancient West Asian seal imagery and practices. Depending on availability, the project incorporates diverse types of visual records, including photographs, manual line-drawings, 3D scans, RTI imaging, and virtual roll-outs. While high technical homogeneity is not the primary goal, the combination of these sources ensures that the essential pictorial and textual features of seals are captured for annotation and analysis. Automated image processing is increasingly being applied to produce standardised, computerised line drawings, guided by best-practice frameworks such as IIIF. Collaboration with other institutions ensures access to complementary imaging techniques and datasets. Open Access images and derivative line-drawings are, in most cases, provided under CC-BY-SA licenses in accordance with copyright agreements.
Annotation of image and text

The annotation of pictorial elements is performed using object detection methods that automatically identify and localise individual pictorial elements in images using bounding boxes. While this initial detection step works reliably, the subsequent classification into specific categories remains challenging due to variable image quality and the specificity of seal iconography. All results are therefore reviewed and validated by project members to guarantee accuracy. Textual components, including seal inscriptions and information from sealed artefacts such as cuneiform tablets, are segmented and processed using a structured approach to capture named entities and other information relevant to reconstructing social use contexts. Existing transliterations and translations from publications and online repositories are incorporated and checked by KIŠIB team members for consistency and completeness. Named entities are extracted, disambiguated and linked to enable social network analysis. KIŠIB follows recent advances in natural language processing and AI-assisted workflows to further automate these tasks.
User interfaces
KIŠIB provides web-based interfaces for project members and collaborators to efficiently enter, search, and edit data, while public frontends allow users to explore and query the corpus. Search and browsing functions combine textual queries, controlled vocabulary terms, and approximate string matching to facilitate access for both experts and non-specialists. Simple spatiotemporal maps and network visualisations illustrate interactions between objects, images, persons, and institutions. For more advanced analyses, users can export data via APIs or SPARQL endpoints, supporting computational research in fields such as digital prosopography and cultural analytics.
By combining expert knowledge with machine-learning support, semantic modelling, and flexible digital infrastructure, KIŠIB aims to provide a robust, sustainable, and interoperable framework for the study of West Asian seals and sealings, ensuring that both visual and textual evidence can be fully exploited for research, teaching, and public engagement.